A couple of plugins are provided for a quick integration of UDPipe POS taggers into the analysis system.
The main issue in integrating POS taggers into the complex Pythia analysis flow is that Pythia remains agnostic with respect to the input text format, and most times it analyzes marked text (e.g. XML) rather than plain text. Also, its flow is fully customizable, so your own tokenization algorithm might well be different from that adopted by the chosen UDPipe model.
As a recap, the figure below shows the Pythia’s analysis components in their flow:
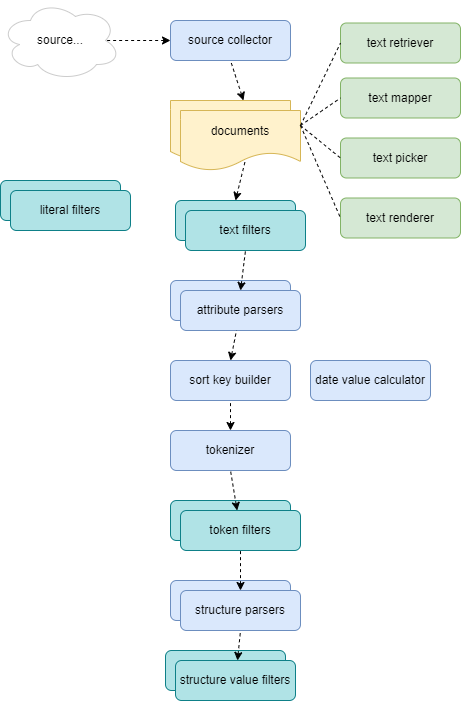
To solve these issues while still being compliant with its open and modular architecture, Pythia provides a couple of plugins designed to work together: the UDP text filter and the UDP token filter.
The UDP text filter belongs to the family of text filters components, i.e. it’s a filter applied once to the whole document, at the beginning of the analysis process. The purpose of this filter is not changing the document’s text, but only submitting it to the UDPipe service, in order to get back POS tags for its content.
This submission may either happen at once, when text documents have a reasonable size; or may be configured to happen in chunks, so that POST requests to the UDPipe service have a smaller body. In this case, the text filter is designed in such a way to avoid splitting a sentence into different chunks (unless it happens to be longer than the maximum allowed chunk size, as configured in the profile).
Whatever the submission details, in the end this filter collects all the POS tags for the document’s content. So, it’s just a middleware component inserted at the beginning of the analysis flow, after some filters like the XML filler filter have been applied to ‘neutralize’ eventual markup (which of course must be excluded from UDPipe processing).
Later on, after the text has been tokenized, the UDP token filter comes into play. Its task is matching the token being filtered with the token (if any) defined by UDPipe, extract all the POS data from it, and store into the target index the subset of them specified by the analysis configuration.
Token matching happens in a rather mechanical way: as the filter has the character-based offset of the token being processed and its length, it just scans the POS data got by the UDP text filter and matches the first UDPipe token overlapping it. This is made possible by the fact that the text filter requested the POS data together with the offsets and extent of each token (passed via the CONLLU Misc field). So, whatever the original format of the document and the differences in tokenization, in most cases this produces the expected result and thus provides a quick way of incorporating UDPipe data in the index.
Example
As a configuration example, consider this real-world profile.
This defines an analysis flow which applies document filtering as follows:
- draws TEI documents from the file system (
source-collector.file); - collects the spans of elements with tag
abbrornum(text-filter.xml-local-tag-list), as they will be consumed later to help the UDP chunker not being fooled by stops not corresponding to sentence ends; - blank fills all the XML
tei:expanelements (which thus get removed from text, as they are expansions of abbreviations, i.e. inserted text;text-filter.xml-tag-filler); - blank-fills XML markup and the whole TEI header (
text-filter.tei; this removes only tags, not their content); - normalizes quotation marks;
- applies an UDPipe text filter to the resulting document. This filter uses a model for the Italian language, and while submitting the text to the service chunks it. Chunking happens by locating a regular expression corresponding to sentence end (here
(?<![0-9])[.?!](?![.?!]), i.e. sentence-end punctuation not preceded by digits - as these texts have a lot of numbered lists - and eventually preceded by other sentence-end punctuation), but not inside elementsabbrornum. Note that the text received by this filter has no tags at all (by virtue of (4)), but the data context of the filter carries the original elements positions collected at (2).
After this document filtering, some attribute parsers are used to extract document metadata from some specific locations in the TEI header, and from an additional CSV file. This is because for security reasons more sensitive metadata are not kept in the TEI header, but rather isolated in an external file.
Then, a standard tokenizer is used, which essentially splits text at whitespaces. This tokenizer has 3 filters, among which the UDPipe token filter, which extracts token metadata from the POS data previously collected by the UDPipe text filter.
Finally, a number of structure filters are used to extract text structures corresponding to paragraphs (as they are relevant for the study of this kind of prose), sentences, and a number of “ghost” structures defined for the purpose of adding further metadata to the tokens they include (e.g. foreign to mark each token inside it as a foreign-language word, the main language of the document being Italian).
At the bottom of the configuration you find the components related to text reading: text retriever, mapper, passages picker, and renderer (used to convert the original TEI document into HTML via a XSLT transformation).
{
"SourceCollector": {
"Id": "source-collector.file",
"Options": {
"IsRecursive": false
}
},
"TextFilters": [
{
"Id": "text-filter.xml-local-tag-list",
"Options": {
"Names": [
"abbr",
"num"
]
}
},
{
"Id": "text-filter.xml-tag-filler",
"Options": {
"Tags": [
"tei:expan"
],
"Namespaces": [
"tei=http://www.tei-c.org/ns/1.0"
]
}
},
{
"Id": "text-filter.tei"
},
{
"Id": "text-filter.quotation-mark"
},
{
"Id": "text-filter.udp",
"Options": {
"Model": "italian-isdt-ud-2.10-220711",
"MaxChunkLength": 5000,
"ChunkTailPattern": "(?<![0-9])[.?!](?![.?!])",
"BlackTags": [
"abbr",
"num"
]
}
}
],
"AttributeParsers": [
{
"Id": "attribute-parser.xml",
"Options": {
"Mappings": [
"title=/tei:TEI/tei:teiHeader/tei:fileDesc/tei:titleStmt/tei:title"
],
"DefaultNsPrefix": "tei",
"Namespaces": [
"tei=http://www.tei-c.org/ns/1.0"
]
}
},
{
"Id": "attribute-parser.fs-csv",
"Options": {
"SourceFind": "\\.xml$",
"SourceReplace": ".xml.meta",
"NameColumnIndex": 0,
"ValueColumnIndex": 1,
"ValueTrimming": true
}
}
],
"DocSortKeyBuilder": {
"Id": "doc-sortkey-builder.standard"
},
"DocDateValueCalculator": {
"Id": "doc-datevalue-calculator.unix",
"Options": {
"Attribute": "data",
"YmdPattern": "(?<y>\\d{4})(?<m>\\d{2})(?<d>\\d{2})",
"YmdAsInt": true
}
},
"Tokenizer": {
"Id": "tokenizer.standard",
"Options": {
"TokenFilters": [
{
"Id": "token-filter.udp",
"Options": {
"Props": 43
}
},
{
"Id": "token-filter.ita"
},
{
"Id": "token-filter.len-supplier",
"Options": {
"LetterOnly": true
}
}
]
}
},
"StructureParsers": [
{
"Id": "structure-parser.xml",
"Options": {
"Definitions": [
{
"Name": "p",
"XPath": "/tei:TEI/tei:text/tei:body/tei:p",
"ValueTemplate": "1"
},
{
"Name": "abbr",
"XPath": "//tei:abbr",
"ValueTemplate": "1",
"TokenTargetName": "abbr"
},
{
"Name": "address",
"XPath": "//tei:address",
"ValueTemplate": "1",
"TokenTargetName": "address"
},
{
"Name": "date",
"XPath": "//tei:date",
"ValueTemplate": "{t}",
"ValueTemplateArgs": [
{
"Name": "t",
"Value": "."
}
],
"ValueTrimming": true,
"TokenTargetName": "address"
},
{
"Name": "email",
"XPath": "//tei:email",
"ValueTemplate": "1",
"TokenTargetName": "email"
},
{
"Name": "foreign",
"XPath": "//tei:foreign",
"ValueTemplate": "{l}",
"ValueTemplateArgs": [
{
"Name": "l",
"Value": "./@xml:lang"
}
],
"TokenTargetName": "foreign"
},
{
"Name": "hi-b",
"XPath": "//tei:hi[contains(@rend, 'b')]",
"ValueTemplate": "1",
"TokenTargetName": "b"
},
{
"Name": "hi-i",
"XPath": "//tei:hi[contains(@rend, 'i')]",
"ValueTemplate": "1",
"TokenTargetName": "i"
},
{
"Name": "hi-u",
"XPath": "//tei:hi[contains(@rend, 'u')]",
"ValueTemplate": "1",
"TokenTargetName": "u"
},
{
"Name": "num",
"XPath": "//tei:num",
"ValueTemplate": "1",
"TokenTargetName": "n"
},
{
"Name": "org-name",
"XPath": "//tei:orgName[@type='m']",
"ValueTemplate": "{t}",
"ValueTemplateArgs": [
{
"Name": "t",
"Value": "."
}
],
"ValueTrimming": true,
"TokenTargetName": "org-m"
},
{
"Name": "org-name",
"XPath": "//tei:orgName[@type='f']",
"ValueTemplate": "{t}",
"ValueTemplateArgs": [
{
"Name": "t",
"Value": "."
}
],
"ValueTrimming": true,
"TokenTargetName": "org-f"
},
{
"Name": "pers-name",
"XPath": "//tei:persName[@type='mn']",
"ValueTemplate": "{t}",
"ValueTemplateArgs": [
{
"Name": "t",
"Value": "."
}
],
"ValueTrimming": true,
"TokenTargetName": "pn-m"
},
{
"Name": "pers-name",
"XPath": "//tei:persName[@type='fn']",
"ValueTemplate": "{t}",
"ValueTemplateArgs": [
{
"Name": "t",
"Value": "."
}
],
"ValueTrimming": true,
"TokenTargetName": "pn-f"
},
{
"Name": "pers-name",
"XPath": "//tei:persName[@type='s']",
"ValueTemplate": "{t}",
"ValueTemplateArgs": [
{
"Name": "t",
"Value": "."
}
],
"ValueTrimming": true,
"TokenTargetName": "pn-s"
},
{
"Name": "place-name",
"XPath": "//tei:placeName",
"ValueTemplate": "{t}",
"ValueTemplateArgs": [
{
"Name": "t",
"Value": "."
}
],
"ValueTrimming": true,
"TokenTargetName": "tn"
}
],
"Namespaces": [
"tei=http://www.tei-c.org/ns/1.0",
"xml=http://www.w3.org/XML/1998/namespace"
]
},
"Filters": [
{
"Id": "struct-filter.standard"
}
]
},
{
"Id": "structure-parser.xml-sentence",
"Options": {
"RootXPath": "/tei:TEI/tei:text/tei:body",
"StopTags": [
"head"
],
"NoSentenceMarkerTags": [
"abbr",
"num"
],
"Namespaces": [
"tei=http://www.tei-c.org/ns/1.0"
]
}
}
],
"TextRetriever": {
"Id": "text-retriever.file"
},
"TextMapper": {
"Id": "text-mapper.xml",
"Options": {
"Definitions": [
{
"Name": "body",
"XPath": "/tei:TEI/tei:text/tei:body",
"ValueTemplate": "act"
},
{
"Name": "p",
"ParentName": "body",
"XPath": "./tei:p",
"DefaultValue": "paragraph",
"ValueTemplate": "{t}",
"ValueTemplateArgs": [
{
"Name": "t",
"Value": "."
}
],
"ValueMaxLength": 60,
"ValueTrimming": true,
"DiscardEmptyValue": true
}
],
"Namespaces": [
"tei=http://www.tei-c.org/ns/1.0"
],
"DefaultNsPrefix": "tei"
}
},
"TextPicker": {
"Id": "text-picker.xml",
"Options": {
"HitOpen": "<hi rend=\"hit\">",
"HitClose": "</hi>",
"Namespaces": [
"tei=http://www.tei-c.org/ns/1.0",
"xml=http://www.w3.org/XML/1998/namespace"
],
"DefaultNsPrefix": "tei"
}
},
"TextRenderer": {
"Id": "text-renderer.xslt",
"Options": {
"Script": "c:\\users\\dfusi\\desktop\\ac\\read.xsl",
"ScriptRootElement": "{http://www.tei-c.org/ns/1.0}body"
}
}
}
Dissecting the Example
(1) SourceCollector: a file-based source is used, i.e. the documents to be indexed will be enumerated from the file system. Specifically, the received source input will represent a directory, which will not be recursed.
(2) TextFilters: document-wide text filters:
text-filter.xml-local-tag-list: collect the spans of elements with tagabbrornum, as they will be consumed later, to help the UDP chunker not being fooled by stops not corresponding to sentence ends;text-filter.xml-tag-filler: blank-fillexpanXML tags, as we do not want abbreviations expansions (which are not part of the original text) to be indexed.text-filter.tei: blank-fill TEI header.text-filter.quotation-mark: normalize quotation marks.text-filter.udp: analyze the text via the online UDPipe service, using the specified model for the Italian language, and ignoring the content ofabbrornumtags.
(3) AttributeParsers: extract document attributes:
attribute-parser.xml: extract metadata (here just the title) from the TEI header.attribute-parser.fs-csv: extract metadata from the ancillary metadata file for each source document. This is a comma-separated values document, named after the text document with a.metasuffix. Metadata are name=value pairs, name being at column 0, and value at column 1. To ensure that unnoticed blanks do not enter the database at the start or end of each value, values are trimmed.
(4) DocSortKeyBuilder: build the default sort key for the documents. This just uses the standard builder.
(5) DocDateValueCalculator: calculate a computable value for each document’s date. This is got from the data attribute (actually found in the metadata ancillary files), having format YYYYMMDD. The pattern is analyed with a regular expression, and its UNIX date value becomes the calculated value.
(6) Tokenizer: tokenize using a standard tokenizer. Token filters used:
token-filter.udp: UDP token filter. This injects UDP attributes into each token. Props specifies which UDP properties should be considered, and is a numeric value built by summing all these bit values:
| property | value |
|---|---|
| 1 | lemma |
| 2 | UPosTag |
| 4 | XPosTag |
| 8 | Feats |
| 16 | Head |
| 32 | DepRel |
| 64 | Misc |
So, here 43=lemma, UPosTag, Feats, DepRel.
token-filter.ita: Italian filter.token-filter.len-supplier: this filter supplies a length attribute for each token, counting its letter characters.
(7) StructureParsers: structures and ghost-structures.
(8) TextRetriever: the component used to retrieve document’s text. This is a file-based retriever, i.e. it reads a file.
(9) TextMapper: the text map builder.
(10) TextPicker: the text portion picker.
(11) TextRenderer: the text renderer.