- Source Collectors
- Literal Filters
- Text Filters
- Attribute Parsers
- Document Sort Key Builders
- Date Value Calculators
- Tokenizers
- Token Filters
- Structure Parsers
- Structure Value Filters
- Text Retrievers
- Text Mappers
- Text Pickers
- Text Renderers
This is an overview of some stock components coming with Pythia. Everyone can add new components at will, and use them in the Pythia profile.
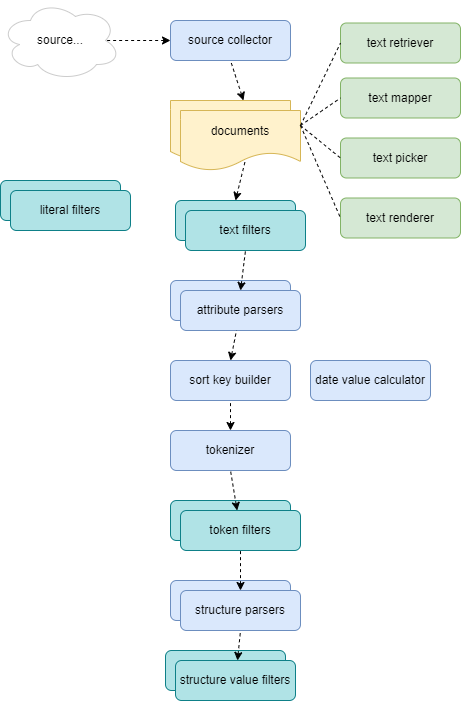
Source Collectors
💡 Components which collect a list of documents from a source.
File Source Collector
- 🔑 tag:
source-collector.file(inCorpus.Core.Plugin)
File system based source collector. This collector just enumerates the files matching a specified mask in a specified directory. Its source is the directory name.
Options:
IsRecursive: true to recurse the specified directory.
Literal Filters
💡 Filters applied to the literal values of Pythia query pairs.
Italian Literal Filter
- 🔑 tag:
literal-filter.ita(inPythia.Core.Plugin)
Italian literal filter. This removes all the characters which are not letters or apostrophe, strips from them all diacritics, and lowercases all the letters.
Text Filters
💡 Filters applied to document’s text as a whole.
Quotation Mark Text Filter
- 🔑 tag:
text-filter.quotation-mark(inCorpus.Core.Plugin)
This filter just replaces U+2019 (right single quotation mark) with an apostrophe (U+0027) when it is included between two letters.
TEI Text Filter
- 🔑 tag:
text-filter.tei(inCorpus.Core.Plugin)
Filter for preprocessing TEI documents. This filter blank-fills the whole TEI header (assuming it’s coded as <teiHeader>), and each tag in the document (unless instructed to keep the tags).
Options:
KeepTags: true to keep tags in the TEI’s text. The default value is false. Even when true, the TEI header is cleared anyway.
UDP Text Filter
- 🔑 tag:
text-filter.udp(inPythia.Udp.Plugin)
UDPipe-based text filter. This filter analyzes the whole text using the UDPipe API service, storing the results in the filter’s context. Later, this will be available to token filters, which will apply attributes from it. Thus, the received text is only used to extract from it POS data, and is not altered in any way.
Options:
Model: the UDPipe model’s name (e.g.latin-perseus-ud-2.10-220711,italian-isdt-ud-2.10-220711, etc.).MaxChunkLength: the maximum length of the chunk of text to submit to UDP processor for analysis. This may be required when dealing with API-based UDPipe processors, to limit the amount of text passed to the endpoint via form encoding. Chunks are split according to sentence end markers, in order to avoid splitting a sentence. You should ensure that the maximum chunk length is greater than or equal to the maximum length of a sentence.
XML Tag Filler Text Filter
- 🔑 tag:
text-filter.xml-tag-filler
Filter for preprocessing XML documents. This blank-fills with spaces all the matching tags and their content. For instance, say you have a TEI document with choice including abbr and expan, and you want to blank-fill all the expan’s to avoid indexing them: you can use this text filter to replace expan elements and all their content with spaces, thus effectively removing them from indexed text, while keeping offsets and document’s length unchanged.
Options:
Tags: the list of tag names to be blank-filled with all their content. When using namespaces, add a prefix (liketei:expan) and ensure it is defined inNamespaces. If the tags list is empty, all the tags (but not their content) will be blank-filled.Namespaces: a set of optional key=namespace URI pairs. Each string has formatprefix=namespace. When dealing with documents with namespaces, add all the prefixes you will use inTagshere, so that they will be expanded before processing.
XML Local Tag List Text Filter
- 🔑 tag:
text-filter.xml-local-tag-list
XML local (=no namespace) tags list text filter. This extracts a list of XML tag entries, one for each of the tags found in the text and listed in the filter’s options. Each entry has the tag name and position. Entries are stored in indexing context data, while text is not changed at all.
Other components used later in the pipeline (like the UDP filters) may take advantage of the tag list collected by this filter to drive their processing.
Attribute Parsers
💡 Components which extract attributes (metadata) from documents.
XML Attribute Parser
- 🔑 tag:
attribute-parser.xml(inCorpus.Core.Plugin)
XML document’s attributes parser. This extracts document’s metadata from its XML content (e.g. a teiHeader in a TEI document).
Options:
Mappings: an array of strings, one for each mapping. A mapping contains:- attribute name: the attribute target name, eventually suffixed with
+when more than 1 values for it are allowed. When not set (which is the default value), the search stops at the first match. - equals: the equals sign (
=) introduces the search expression. - XPath: a full XPath 1.0 expression to locate the attribute’s value(s). Namespace prefixes can be used, either from the document or from
Namespaces. - attribute type (optional): the type of the attribute, divided from the previous token by a space; it is either
[T]=text or[N]=numeric. - regular expression: a regular expression pattern, divided from the previous token by a space, used to further filter the attribute’s value and/or parse it. The whole expression is captured, unless a group is specified; in this case, the first capturing group is captured. For instance, the date expressed by a year value could be mapped as
date-value=/tei:TEI/tei:teiHeader/tei:fileDesc/tei:titleStmt/tei:date/@when [N] [12]\d{3}.
- attribute name: the attribute target name, eventually suffixed with
Namespaces: a set of optional key=namespace URI pairs. Each string has formatprefix=namespace. When dealing with documents with namespaces, add all the prefixes you will use inMappingshere, so that they will be expanded before processing.DefaultNsPrefix: gets or sets the default namespace prefix. When this is set, and the document has a default empty-prefix namespace (xmlns="URI"), all the XPath queries get their empty-prefix names prefixed with this prefix, which in turn is mapped to the default namespace. This is because XPath treats the empty prefix as the null namespace. In other words, only prefixes mapped to namespaces can be used in XPath queries. This means that if you want to query against a namespace in an XML document, even if it is the default namespace, you need to define a prefix for it. So, if for instance you have a TEI document with a defaultxmlns="http://www.tei-c.org/ns/1.0", and you define mappings with XPath queries like//body, nothing will be found. If instead you setDefaultNsPrefixtoteiand then use this prefix in the mappings, like//tei:body, this will find the element. See this SO post for more.
Excel Attribute Parser
- 🔑 tag:
attribute-parser.fs-excel
File-system based Excel XLS/XLSX attribute parser. This parser assumes that additional metadata for the document being parsed can be got from an Excel file with a path which can be derived from the document’s source. It opens the file and reads metadata from 2 designed columns, one representing names and the other representing values. Additionally, it can rewrite the names as specified by its configuration options. The file format used is either the new Office Open XML format (XLSX), or the legacy one (XLS), according to the extension. For any extension different from xls, the new format is assumed.
Options:
SourceFind: the regular expression pattern to find in the source when replacing it with SourceReplace. If this is not set, the document’s source itself will be used. The document extension should be xlsx or xls for the legacy Excel format.SourceReplace: the text to replace when matching SourceFind in the document’s source, so that the corresponding Excel file path can be built from it.SheetName: the name of the sheet to load data from. You can set either this one, orSheetIndex. If both are set,SheetNamehas precedence.SheetIndex: the index of the sheet to load data from (default=0). You can set either this one, orSheetName. If both are set,SheetNamehas precedence.NameColumnIndex: the index of the name column in the Excel file.ValueColumnIndex: the index of the value column in the Excel file.ValueTrimming: a value indicating whether attribute values should be trimmed when read from the Excel file. Attribute names are always trimmed.NameMappings: the name mappings. This is a list of name=value pairs, where each name is a metadata attribute name as found in the Excel file, and each value is its renamed counterpart. You can use this to rename metadata found in Excel files, or to skip some of them by mapping them to an empty string. The name can end with#to indicate that the attribute has a numeric rather than a string value. You can thus use mappings even when you don’t want to rename attributes, but you want to set their type.
Document Sort Key Builders
💡 Components which build a sort-key for documents, so that they get ordered in a specific way when presented.
Standard Document Sort Key Builder
- 🔑 tag:
doc-sortkey-builder.standard(inCorpus.Core.Plugin)
Standard sort key builder. This builder uses author, title and year attributes to build a sort key.
Date Value Calculators
💡 Components which calculate an approximate numeric value from documents dates.
Standard Date Value Calculator
- 🔑 tag:
doc-datevalue-calculator.standard(inCorpus.Core.Plugin)
Standard document’s date value calculator, which just copies it from a specified document’s attribute.
Options:
Attribute: the name of the document’s attribute to copy the date value from.
Unix Date Value Calculator
- 🔑 tag:
doc-datevalue-calculator.unix
Unix-date modern date value calculator. This is based on an attribute with some indication of year and eventually month and day, and calculates the Unix time from it. Alternatively, it can also provide the result as just the integer number resulting from concatenating YYYYMMDD, like 20140420 from Y=2014, M=4, D=20. This is a more user-friendly value for a simple date.
Options:
Attribute: the name of the document’s attribute to read the date expression from.YmdPattern: the year-month-day pattern to match from theAttribute’s value. The pattern should provide groups namedyfor year,mfor month, anddfor day. At least the year group should be defined. For instance, from a value like20100420we could get year=2004, month=04, and day=20 using pattern(?<y>\d{4})(?<m>\d{2})(?<d>\d{2}).YmdAsInt: a value indicating whether instead of calculating the Unix time the value should just be an integer resulting from concatenatingYYYYMMDD.
Tokenizers
💡 Text tokenizers.
Standard Tokenizer
- 🔑 tag:
tokenizer.standard(inPythia.Core.Plugin)
A standard tokenizer, which splits tokens at whitespaces or when ending with an apostrophe, which is included in the token.
Whitespace Tokenizer
- 🔑 tag:
tokenizer.whitespace(inPythia.Core.Plugin)
Simple whitespace tokenizer.
POS Tagging XML Tokenizer
- 🔑 tag:
tokenizer.pos-tagging(inPythia.Core.Plugin)
Legacy POS-tagging XML tokenizer, used for both real-time and deferred tokenization. This tokenizer uses an inner tokenizer for each text node in an XML document. This tokenizer accumulates tokens until a sentence end is found; then, if it has a POS tagger, it applies POS tags to all the sentence’s tokens; otherwise, it adds an s0 attribute to each sentence-end token. In any case, it then emits tokens as they are requested. This behavior is required because POS tagging requires a full sentence context.
Note that the sentence ends are detected by looking at the full original text, as looking at the single tokens, even when unfiltered, might not be enough; tokens which become empty when filtered would be skipped, and tokens and sentence-end markers might be split between two text nodes, e.g. <hi>test</hi>. where the stop is located in a different text node.
Token Filters
💡 Token filters. Each tokenizer can have any number of such filters.
File System Cache Supplier Token Filter
- 🔑 tag:
token-filter.cache-supplier.fs(inPythia.Core.Plugin)
Attributes supplier token filter, drawing selected attributes from the tokens stored in a file-system based cache. This filter is used in deferred POS tagging, to supply POS tags from a tokens cache, which is assumed to have been processed by a 3rd-party POS tagger. Typically, this adds a pos attribute to each tagged token, which is later consumed by this filter during indexing.
Options:
CacheDirectory: the tokens cache directory.SuppliedAttributes: the names of the attributes to be supplied from the cached tokens. All the other attributes of cached tokens are ignored.
Alnum Apos Token Filter
- 🔑 tag:
token-filter.alnum-apos(inPythia.Core.Plugin)
A token filter which removes from the token’s value any non- letter / digit / ' character.
Lower Alnum Apos Token Filter
- 🔑 tag:
token-filter.lo-alnum-apos(inPythia.Core.Plugin)
A token filter which removes from the token’s value any non-letter / digit / ' character and lowercases the letters.
Italian Token Filter
- 🔑 tag:
token-filter.ita(inPythia.Core.Plugin)
Italian token filter. This filter removes all the characters which are not letters or apostrophe, strips from them all diacritics, and lowercases all the letters.
Italian Tagged Token Filter
- 🔑 tag:
token-filter.ita-tagged(inPythia.Core.Plugin)
Italian tagged token filter. This filter normally removes all the characters which are not letters or apostrophe, strips from them all diacritics, and lowercases all the letters. Yet, for those tokens included in the specified list of tags, it will just lowercase them and trim initial and final punctuation-like characters, as specified by options. This is useful for tokens representing numbers, dates, email addresses, etc. The filter relies on the XML local tags list text filter to determine whether a token is inside a tag or not.
Options:
Tags: the tags to be treated as containers for tokens to be filtered in a special way like numbers, dates, or email addresses. The default tags are:date,email,num.TrimmedEdges: the trimmed edges string; this includes any character which should be removed from the start or the end of the special token. If null, no trimming is performed. The default is a set of common punctuation characters like brackets, punctuation, quotes, etc.
Length Supplier Token Filter
- 🔑 tag:
token-filter.len-supplier(inPythia.Core.Plugin)
Token value’s length supplier. This filter just adds an attribute to the token, with name len (or the one specified in its options) and value equal to the length of the token’s value, counting only its letters.
Options:
AttributeName: the name of the attribute supplied by this filter. The default islen.LetterOnly: a value indicating whether only letters should be counted when calculating the token value’s length.
Punctuation Token Filter
- 🔑 tag:
token-filter.punctuation(inPythia.Core.Plugin)
A token filter which injects punctuation attributes for punctuation at the left/right (lp and rp) of a token. All the punctuation character(s) at the left up to the first non-punctuation character are considered as lp; all the punctuation character(s) at the right leftwards, up to the first non-punctuation character and before lp characters are considered as rp. Punctuation characters are any Unicode punctuation unless you specify a whitelist or a blacklist.
Options:
Punctuations: a string with punctuation character(s), representing a whitelist or a blacklist according toListType. If not specified, any Unicode punctuation will be included.ListType: the type of thePunctuationslist: 0=none, 1=whitelist, -1=blacklist.
UDP Token Filter
- 🔑 tag:
token-filter.udp(inPythia.Udp.Plugin)
UDP-based token filter. This filter adds new attributes to the token by getting them from the filter’s context sentences, and assumed to be previously collected by an UdpTextFilter. For CONLLU token properties, see https://lindat.mff.cuni.cz/services/udpipe/ for the CONLLU token.
Options:
UdpTokenProps: a numeric 7-bits value, where each bit represents a CONLLU token property to be stored in the index. For instance, 43 (=hex 2B) meansLemma(1),UPosTag(2),Feats(8),DepRel(32). Values are defined as follows (default isLemma,UPosTag,XPosTag,DepRel):Lemma= 1UPosTag= 2XPosTag= 4Feats= 8 (=one attribute per feature, named after it, and eventually prefixed)Head= 16DepRel= 32Misc= 64
Prefix: the optional prefix to add before each attribute name as derived from UDP.FeatPrefix: the optional prefix to add to each feature name attribute.
| Misc | DepRel | Head | Feats | XPosTag | UPosTag | Lemma |
|---|---|---|---|---|---|---|
| 64 | 32 | 16 | 8 | 4 | 2 | 1 |
Structure Parsers
💡 Components which detect textual structures of any extent (e.g. sentence, verse, etc.) in a document.
XML Sentence Parser
- 🔑 tag:
structure-parser.xml-sentence(inPythia.Core.Plugin)
Sentence structure parser for XML documents.
Options:
DocumentFilters: a list ofname=valuepairs, representing a document’s attribute name and value to be matched. Any of these pairs should be matched for the parser to be applied. If not specified, the parser will be applied to any document.RootXPath: the XPath 1.0 expression targeting the root path. This is the path to the element to be used as the root for this parser; when specified, sentences will be searched only whithin this element and all its descendants. For instance, in a TEI document you will probably want to limit sentences to the contents of thebody(/tei:TEI//tei:body) ortext(/tei:TEI//tei:text) element only. If not specified, the whole document will be parsed. You can use namespace prefixes in this expression, either from the document or fromNamespaces.StopTags: list of stop tags. A “stop tag” is an XML tag implying a sentence stop when closed; for instance,tei:headin a TEI document, as a title is anyway a “sentence”, distinct from the following text, whether it ends with a stop or not. Each tag gets filled with spaces, while a stop tag gets filled with a full stop followed by spaces. When using namespaces, add a prefix (liketei:body) and ensure it is defined inNamespaces.NoSentenceMarkerTags: the list of tag names whose content should be ignored when detecting sentence end markers. For instance, say you have a TEI document withabbrelements containing abbreviations with dot(s); in this case, you can add abbr to this list, so that all the dots inside it are ignored. When using namespaces, add a prefix (liketei:abbr) and ensure it is defined inNamespaces.Namespaces: a set of optional key=namespace URI pairs. Each string has formatprefix=namespace. When dealing with documents with namespaces, add all the prefixes you will use inRootPathorStopTagshere, so that they will be expanded before processing.SentenceEndMarkers: the list of characters which are used as sentence end markers. The default value is.?!plus U+037E (Greek question mark).
XML Structure Parser
- 🔑 tag:
structure-parser.xml(inPythia.Core.Plugin)
A parser for element-based structures in XML documents. This parser uses a mapping between any element in the XML document and a corresponding target structure.
Options:
DocumentFilters: a list ofname=valuepairs, representing a document’s attribute name and value to be matched. Any of these pairs should be matched for the parser to be applied. If not specified, the parser will be applied to any document.Definitions: list of structure definitions (see below).Namespaces: a set of optional key=namespace URI pairs. Each string has formatprefix=namespace. When dealing with documents with namespaces, add all the prefixes you will use inRootPathorDefinitionshere, so that they will be expanded before processing.BufferSize: the size of the structures buffer. Structures are flushed to the database only when the buffer is filled, thus avoiding excessive pressure on the database. The default value is 100.
The core configuration element here is the structure definition, which is an object with these properties:
Name: the target structure name.Type: the target structure value type: 0=text (default), 1=number.TokenTargetName: the name of the token target. When this is not null, it means that the structure definition targets a token rather than a structure (this is named a “ghost structure”). This happens when you want to add attributes to the tokens which appear inside specific structures, but you do not want these structures to be stored as such, as their only purpose is marking the included tokens. For instance, a structure corresponding to the TEIforeignelement marks a token as a foreign word, but it should not be stored among structures. As anyway it depends on markup, and thus would be invisible to tokenizers, it is the structure wrapping it (theforeignelement) which will be detected as such, and then just used to mark each token inside it.XPath: the XPath 1.0 expression targeting the XML element to find. If the expression does not target an XML element, the mapping will be ignored.ValueTemplate: the template or literal value to assign to the structure. This is either a constant value, or a template with placeholders between braces ({}). For instance,Chapter {n}is a template, whileNew Sectionis a constant. Placeholders are replaced by values taken fromValueTemplateArgs, except when they start with a$, which is reserved for special macros. Currently, the only defined macro is the “spacer”$_. This is replaced with a space unless at end/start of value, or the template already has a space before it, and can be used to append several optional values with a single space between them. For instance, you might have a template like{type}{$_}{n}, where arguments come from optional attributes@typeand@n. In this case, when onlytypeis found you will get e.g.12rather than a space +12, but when both are found you will get e.g.poem 12.ValueTemplateArgs: an array of objects, each with properties:Name: the argument name.Value: the argument value, which is an XPath 1.0 expression relative to the target element, as found by the definition’sXPathproperty. For instance,./@nlooks for an attributenin the target element.
ValueMaxLength: an optional maximum length limit (in characters) for the value. When set, any value longer than this limit gets cut.DiscardEmptyValue: true to discard nodes having an empty value, i.e. a value which is either emptyor contains only whitespace(s).
Structure Value Filters
💡 Filters applied to structures values.
Standard Structure Value Filter
- 🔑 tag:
struct-filter.standard(inPythia.Chiron.Plugin)
Standard structure value filter: this removes any character different from letter or digit or apostrophe or whitespace, removes any diacritics from each letter, and lowercases each letter. Whitespaces are all normalized to a single space, and the result is trimmed.
Text Retrievers
💡 Components which retrieve the document’s text from a source.
File Text Retriever
- 🔑 tag:
text-retriever.file(inCorpus.Core.Plugin)
File-system based UTF-8 text retriever. This is the simplest text retriever, which just opens a text file from the file system and reads it.
Options:
FindPattern: an expression used to find a part of the source file path, and replace it with the value inReplacePattern. This can be used to relocate source files once they have been indexed from a different directory.ReplacePattern: this replaces the expression specified byFindPattern. For instance,^E:\\Temp\\Archive\\could be a find pattern, andD:\Jobs\Crusca\Prin2012\Archive\a replace pattern.
PostgreSQL Text Retriever
- 🔑 tag:
text-retriever.sql.pg(inPythia.Sql.PgSql)
PostgreSQL text retriever. This is used to retrieve the document’s text from the index itself, when the index is implemented with PostgreSQL.
Azure BLOB Text Retriever
- 🔑 tag:
text-retriever.az-blob(inCorpus.Core.Plugin)
Microsoft Azure BLOB text retriever. Use this retriever to store document’s texts as Azure BLOBs. The document’s source property refers to the BLOB URI.
Options:
Connection: the Azure connection string.AccountId: the account ID.ContainerName: the name for the Azure container.
Text Mappers
💡 Components which build a navigable, hierarchic text map from a document. A text map is an abstraction modeled as a tree, where each node targets a specific portion of the document. Such maps are used to browse through documents, and to pick portions of text from map nodes.
XML Text Mapper
- 🔑 tag:
text-mapper.xml(inCorpus.Core.Plugin)
A generic XML text mapper. This mapper assumes that a specified element is the root node of the map, and then walks down its tree, inserting nodes only for those elements which match any of the specified paths. Thus, you should provide a single node with an XPath expression targeting the root element for the map, and then as many descendant nodes as required, each with an XPath relative to its parent.
Note that the only requirement is that the descendant node path must target an element which is a descendant of the parent node path; it must not be a direct child, nor there has to be a 1:1 relationship between the map tree and the XML DOM tree.
Options:
Definitions: the text map nodes definitions (see below).Namespaces: a set of optional key=namespace URI pairs. Each string has formatprefix=namespace.DefaultNsPrefix: gets or sets the default namespace prefix. When this is set, and the document has a default empty-prefix namespace (xmlns="URI"), all the XPath queries get their empty-prefix names prefixed with this prefix, which in turn is mapped to the default namespace.
Each node definition has these properties:
Name: the node name. This is an arbitrary name used to identify each node definition, so that you can reference nodes in this configuration.ParentName: the name of the parent node definition. This property is omitted only for the root node definition.DefaultValue: the default value assigned to nodes corresponding to this definition when the value extracted from text is empty.Type: the target structure value type: 0=text (default), 1=number.XPath: the XPath 1.0 expression targeting the XML element to find. If the expression does not target an XML element, the mapping will be ignored.ValueTemplate: the template or literal value to assign to the structure. This is either a constant value, or a template with placeholders between braces ({}). For instance,Chapter {n}is a template, whileNew Sectionis a constant. Placeholders are replaced by values taken fromValueTemplateArgs, except when they start with a$, which is reserved for special macros. Currently, the only defined macro is the “spacer”$_. This is replaced with a space unless at end/start of value, or the template already has a space before it, and can be used to append several optional values with a single space between them. For instance, you might have a template like{type}{$_}{n}, where arguments come from optional attributes@typeand@n. In this case, when onlytypeis found you will get e.g.12rather than a space +12, but when both are found you will get e.g.poem 12.ValueTemplateArgs: an array of objects, each with properties:Name: the argument name.Value: the argument value, which is an XPath 1.0 expression relative to the target element, as found by the definition’sXPathproperty. For instance,./@nlooks for an attributenin the target element.
ValueMaxLength: an optional maximum length limit (in characters) for the value. When set, any value longer than this limit gets cut.DiscardEmptyValue: true to discard nodes having an empty value, i.e. a value which is either emptyor contains only whitespace(s).
Text Pickers
💡 Components which pick a specific, relatively meaningful portion from a text.
XML Text Picker
- 🔑 tag:
text-picker.xml(inCorpus.Core.Plugin)
XML text picker. Options:
HitOpen: the string to be inserted after the hit in the picked text (default is two closing braces).HitClose: the string to be inserted after the hit in the picked text (default is two opening braces).Namespaces: a set of optional key=namespace URI pairs. Each string has formatprefix=namespace.DefaultNsPrefix: gets or sets the default namespace prefix. When this is set, and the document has a default empty-prefix namespace (xmlns="URI"), all the XPath queries get their empty-prefix names prefixed with this prefix, which in turn is mapped to the default namespace.
Text Renderers
💡 Components which render a text for its presentation.
XSLT Text Renderer
- 🔑 tag:
text-renderer.xslt(inCorpus.Core.Plugin)
XSLT-based XML text renderer. This renders an XML document via an XSLT script.
Options:
Script: the path to the XSLT script, or the XSLT script itself. When this value starts with<the latter option is assumed.ScriptArgs: an optional list ofname=valuepairs, representing arguments to be passed to the XSLT script.ScriptRootElement: an optional element name for the root element of the XSLT script (e.g.body). If the XML fragment being rendered lacks this element, it will be wrapped in it before rendering. You can prefix to this name a namespace between braces (e.g. ).IsIndentEnabled: true to enable indented output.
LIZ Text Renderer
- 🔑 tag:
text-renderer.liz-html(Pyhia.Liz.Plugin)
This is a legacy renderer temporarily hosted in the main project, as it’s ready to use when testing. It derives from a corpus of stripped-down TEI documents, with a single default empty namespace and a minimalist set of tags.