- Process
- Profile
- SourceCollector (required)
- LiteralFilters (optional)
- TextFilters (optional)
- AttributeParsers (optional)
- DocSortKeyBuilder (required)
- DocDateValueCalculator (required)
- Tokenizer (required)
- StructureParsers (optional)
- TextRetriever (required)
- TextMapper (required)
- TextPicker (required)
- TextRenderer (optional)
The analysis process starts from document sources to extract documents, tokens and structures from them. As indexing here means getting metadata from the texts and any other sources, the main focus here is on flexibility, attained via modularity.
The process is thus structured into a composable pipeline, whose details are defined by a profile. A profile is a JSON document, and gets stored in the index itself. Documents can use any profile: in fact, each document has its own reference to the profile used to analyze it.
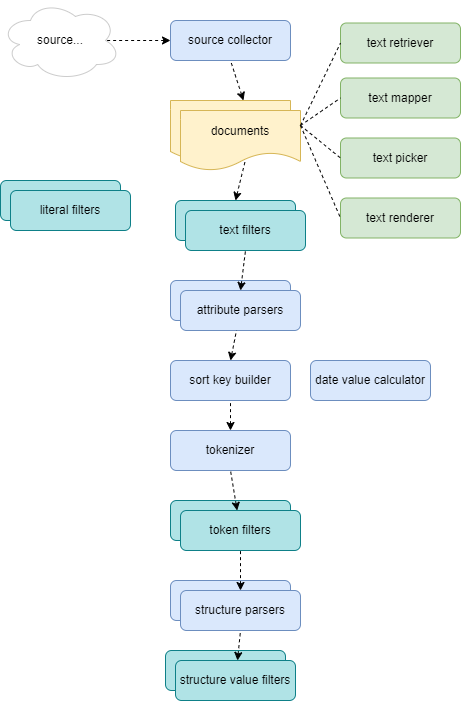
You can look at this example for a full profile.
Process
At the beginning of the indexing process, a source collector is used to collect all the text sources from a specified source. For instance, if you are indexing a folder with some files the file-based source collector will enumerate each file in that folder.
For each source collected in this way, the steps are:
- if a document entity exists in the index for the specified source, its metadata get updated; otherwise, a new entity is created.
- a text retriever is used to fetch the document’s text content. For instance, if indexing some files this will just be a component which loads the text from its file.
- a document attribute parser is used to extract additional metadata for the document from its text. Also, a document sort key builder and a document date value calculator are used to calculate additional metadata for each document.
- optionally, a chain of text filters get applied to the text. These can be used to prepare a text as a whole, before submitting it to the tokenization process.
- the filtered text is tokenized by a tokenizer of choice, and each token is filtered with a chain of token filters.
- eventually, the unfiltered text is analyzed for structures by one or more structure parsers.
The final result is completely self-contained in the index database.
Profile
Each document stored in the index has its profile, which specifies the settings used when indexing or reading it. Documents refer to this profile via an ID, which is an arbitrarily chosen string.
Note that the documents in a database are not required to belong all to the same profile; each document can have its own. Whenever dealing with a specific document, its profile will be used.
The profile is serialized in a JSON file. Inside it, a recurring structure is represented by what we can call a configurable component, having:
- an
Idproperty, and - an optional
Optionsproperty, with a variable schema.
A component named PythiaFactory is responsible for instantiating and configuring the various components specified in the profile.
The sections of the profile are discussed in the following text.
SourceCollector (required)
- section:
SourceCollector; single, configurable. - interface:
ISourceCollector(Corpus).
This is a single configurable component (from the Corpus subsystem).
A source collector is a component which, given a global source of documents, scans it to enumerate all the documents it contains, returning a source string (e.g. a file path, a URI, etc.) for each of them.
For instance, for a file-system based source you would use a FileSourceCollector, which enumerates all the file paths matching a specified mask in a specified folder. Or you might have your documents in a BLOB storage, and use a BLOB-based source collector to retrieve the URIs of all the BLOBs, eventually filtering them.
Once you get the ID of a document, you can use an ITextRetriever instance to retrieve each text from its source. Again, the retriever might be file-based (like FileTextRetriever), BLOB-based (like BlobTextRetriever for Azure BLOBs), etc.
Example:
"SourceCollector": {
"Id": "source-collector.file",
"Options": {
"IsRecursive": false
}
}
In this example we define a file-system based source collector, configured to be non-recursive.
LiteralFilters (optional)
- section:
LiteralFilters; multiple, configurable. - interface:
ILiteralFilter
Literal filters are filters to be applied to the literal values of query pairs when parsing the query. The section is an optional array of configurable components, each representing a filter. Literal filters preprocess the literal value by removing all the noise information which is removed or otherwise handled by the filters using when indexing. For instance, if your index uses an Italian text filter, this removes any non-letter and non-apostrophe character, while lowercasing each letter and removing any diacritics from it. You may then want to apply the same filtering to input text typed from users, so that e.g. if a user types Città in a pair literal value, it gets filtered into citta.
TextFilters (optional)
- section:
TextFilters; multiple, configurable. - interface:
ITextFilter(Corpus)
Text filters are filters to be applied to the source text as a whole, before processing it.
The section is an optional array of configurable components, each representing a text filter.
Each filter gets applied to the source text before indexing it. This filtering process is transparent to the indexing system, which just receives the resulting text, whether filtered or not.
As we are going to use the original (unfiltered) documents to retrieve and display text and search context, these filters should not alter the text length in any way. In fact, any relevant preprocessing for adjusting documents should happen before indexing them (which also favors performance); these text filters are only used either to blank-fill tags in a document, or to fix minimal issues (e.g. a quotation mark used as an apostrophe) when we do not want to alter the original documents.
For instance, the TEI text filter blank-fills the whole TEI header, and each tag in the document. This allows indexing the text content only, withouy any tags, and yet keep the exact position of each indexed token in the source TEI document.
Other filters may be used to fix issues in the source documents without editing them; for instance, the quotation mark filter just replaces U+2019 (right single quotation mark) with an apostrophe (U+0027) when it is included between two letters. This allows differentiating the apostrophe with linguistic meaning from the single quotes.
Example:
"TextFilters": [
{
"Id": "text-filter.tei"
},
{
"Id": "text-filter.quotation-mark"
}
]
AttributeParsers (optional)
- section:
AttributeParsers; multiple, configurable. - interface:
IAttributeParser(Corpus)
A set of optional configurable components. It defines the attributes parsers to be used to extract metadata from documents.
These components are used when documents include metadata, e.g. for TEI documents headers. For instance, an XmlAttributeParser can be used to extract attributes from XML documents using XPath plus an optional regular expression pattern. There, you can specify one or more paths to each piece of metadata, as TEI headers often vary in their structure, even in the same corpus.
For instance, here we want to extract from a TEI header author, title, category, date, and date numeric value, each from the first matching expression in the order specified by the profile:
"AttributeParsers": [
{
"Id": "attribute-parser.xml",
"Options": {
"Mappings": [
"author=/TEI/teiHeader/fileDesc/titleStmt/author",
"title=/TEI/teiHeader/fileDesc/titleStmt/title",
"category=/TEI/teiHeader/fileDesc/titleStmt/title/@type",
"date=/TEI/teiHeader/fileDesc/sourceDesc/bibl/date",
"date=/TEI/teiHeader/fileDesc/titleStmt/date",
"date=/TEI/teiHeader/fileDesc/editionStmt/date",
"date=/TEI/teiHeader/fileDesc/editionStmt/edition/date",
"date-value=/TEI/teiHeader/fileDesc/sourceDesc/bibl/date/@when [N] [12]\\d{3}",
"date-value=/TEI/teiHeader/fileDesc/sourceDesc/bibl/date [N] [12]\\d{3}",
"date-value=/TEI/teiHeader/fileDesc/titleStmt/date/@when [N] [12]\\d{3}",
"date-value=/TEI/teiHeader/fileDesc/titleStmt/date [N] [12]\\d{3}",
"date-value=/TEI/teiHeader/fileDesc/editionStmt/date/@when [N] [12]\\d{3}",
"date-value=/TEI/teiHeader/fileDesc/editionStmt/date [N] [12]\\d{3}",
"date-value=/TEI/teiHeader/fileDesc/editionStmt/edition/date/@when [N] [12]\\d{3}",
"date-value=/TEI/teiHeader/fileDesc/editionStmt/edition/date [N] [12]\\d{3}"
]
}
}
],
DocSortKeyBuilder (required)
- section:
DocSortKeyBuilder; single, configurable. - interface:
IDocSortKeyBuilder(Corpus)
A single configurable component used to build sort-keys for each document. A sort-key is a string which provides a default sort order for indexed documents.
For instance, the standard implementation (StandardDocSortKeyBuilder) uses author, title and year attributes to build a sort key so that documents get sorted in this order.
Example:
"DocSortKeyBuilder": {
"Id": "doc-sortkey-builder.standard"
}
DocDateValueCalculator (required)
- section:
DocDateValueCalculator; single, configurable. - interface:
IDocDateValueCalculator(Corpus)
A single configurable component, which calculates an approximated numeric value representing the datation of each document. This can be used for filtering and sorting documents in chronological order.
For instance, the standard implementation (StandardDocDateValueCalculator) just copies it from a specified document’s attribute, assuming that each attribute has a specific numeric datation metadatum.
Example (here the attribute name is date-value):
"DocDateValueCalculator": {
"Id": "doc-datevalue-calculator.standard",
"Options": {
"Attribute": "date-value"
}
}
Here the calculator is configured to read the date value from an attribute named date-value.
Tokenizer (required)
- section:
Tokenizer; single, configurable. - interfaces:
ITokenizer;ITokenFilter.
A single configurable component, representing the tokenizer used in indexing, with all its filters.
For instance, the standard tokenizer (StandardTokenizer) splits tokens at whitespaces or when ending with an apostrophe, which is included in the token.
Each tokenizer can include zero or more token filters, applied in the order in which they are defined. These filter each token extracted from the document’s text. This allows dropping all the “rumor” textual data before indexing.
For instance, the Italian token filter removes all the characters which are not letters or apostrophe, strips from them all diacritics (in Unicode range 0000-03FF), and lowercases all the letters.
Some filters (named attribute suppliers) may just keep the token’s value unchanged, but add some attributes to it. For instance, the lengths supplier filter just counts the token’s characters or its letters (according to its configuration options), adding them to an attribute named len.
Using the same approach, we could add filters for adding any other kind of metadata to tokens, like e.g. POS data, syllables counts, etc.
Example:
"Tokenizer": {
"Id": "tokenizer.standard",
"Options": {
"TokenFilters": [
{
"Id": "token-filter.ita"
},
{
"Id": "token-filter.len-supplier",
"Options": {
"LetterOnly": true
}
}
]
}
}
StructureParsers (optional)
- section:
StructureParsers; multiple, configurable. - interfaces:
IStructureParser,IStructureValueFilter.
Array of configurable components, listing zero or more structure parsers. Each component parses a specific type of the document’s text structure.
For instance, the XmlStructureParser parses the specified structures defined by XML tags in XML documents.
In this example, 3 structures are parsed for poems, stanzas, and verses.
"StructureParsers": [
{
"Id": "structure-parser.xml",
"Options": {
"Definitions": [
{
"Name": "div",
"XPath": "/tei:TEI/tei:text/tei:body/tei:div",
"ValueTemplate": "{n}{$_}{head}",
"ValuteTemplateArgs": [
{
"Name": "n",
"Value": "./@n"
},
{
"Name": "head",
"Value": "./head"
}
]
},
{
"Name": "lg",
"XPath": "//tei:lg",
"ValueTemplate": "{n}",
"ValuteTemplateArgs": [
{
"Name": "n",
"Value": "./@n"
}
]
},
{
"Name": "l",
"XPath": "//tei:l",
"ValueTemplate": "{n}",
"ValuteTemplateArgs": [
{
"Name": "n",
"Value": "./@n"
}
]
},
{
"Name": "quote",
"XPath": "//tei:quote",
"ValueTemplate": "1",
"TokenTargetName": "q"
},
{
"Name": "persName",
"XPath": "//tei:persName",
"ValueTemplate": "{t}",
"ValuteTemplateArgs": [
{
"Name": "t",
"Value": "./text()"
}
],
"TokenTargetName": "pn"
},
{
"Name": "geogName",
"XPath": "//tei:geogName",
"ValueTemplate": "{t}",
"ValuteTemplateArgs": [
{
"Name": "t",
"Value": "./text()"
}
],
"TokenTargetName": "gn"
}
],
"Namespaces": [
"tei=http://www.tei-c.org/ns/1.0"
]
},
"Filters": [
{
"Id": "struct-filter.standard"
}
]
}
TextRetriever (required)
- section:
TextRetriever; single, configurable. - interface:
ITextRetriever
A single configurable component used to retrieve the document’s text content.
Example:
"TextRetriever": {
"Id": "text-retriever.sql.pg"
}
In this example the text is retrieved directly from the index database (which happens to be PostgreSQL). If instead you are storing it elsewhere, you might want to use a file-based text retriever, or a BLOB-based text retriever, etc.
TextMapper (required)
- section:
TextMapper; single, configurable. - interface:
ITextMapper(Corpus)
A single configurable component used to build the text map of each document.
For instance, the generic XmlTextMapper can be used for XML documents. In this example, the TEI body element is the map’s root node, and each poem (div elements children of body) is a child node:
"TextMapper": {
"Id": "text-mapper.xml",
"Options": {
"Definitions": [
{
"Name": "root",
"XPath": "/tei:TEI/tei:text/tei:body",
"ValueTemplate": "document"
},
{
"Name": "poem",
"ParentName": "root",
"XPath": "./tei:div",
"DefaultValue": "poem",
"ValueTemplate": "{type}{$_}{n}",
"ValueTemplateArgs": [
{
"Name": "type",
"Value": "./@type"
},
{
"Name": "n",
"Value": "./@n"
}
]
}
],
"Namespaces": [
"tei=http://www.tei-c.org/ns/1.0"
],
"DefaultNsPrefix": "tei"
}
}
TextPicker (required)
- section:
TextPicker; single, configurable. - interface:
ITextPicker(Corpus)
A single configurable component used to pick a portion of a document’s text. This is used when reading the text using a map, or when displaying a search hit in its context. As this context is defined by a map, this ensures that the text piece corresponds to a logical partition (e.g. a div or the like) of the source document.
Example:
"TextPicker": {
"Id": "text-picker.xml",
"Options": {
"HitOpen": "<hi rend=\"hit\">",
"HitClose": "</hi>",
"Namespaces": [
"tei=http://www.tei-c.org/ns/1.0"
],
"DefaultNsPrefix": "tei"
}
}
In this sample, the picker is used for XML documents, and assumes that search hits are marked by hi elements with their rend attribute equal to hit.
TextRenderer (optional)
- section:
TextRenderer - interface:
ITextRenderer(Corpus)
A single component used to render the document’s text, usually into HTML format.
Example:
"TextRenderer": {
"Id": "text-renderer.xslt",
"ScriptSource": "c:\\users\\dfusi\\desktop\\pythia-tei\\read.xsl"
}
This defines an XSLT-based renderer used for XML documents.